BigQuery vs ClickHouse Cloud: Equivalent and different concepts
Resource organization
The way resources are organized in ClickHouse Cloud is similar to BigQuery's resource hierarchy. We describe specific differences below based on the following diagram showing the ClickHouse Cloud resource hierarchy:
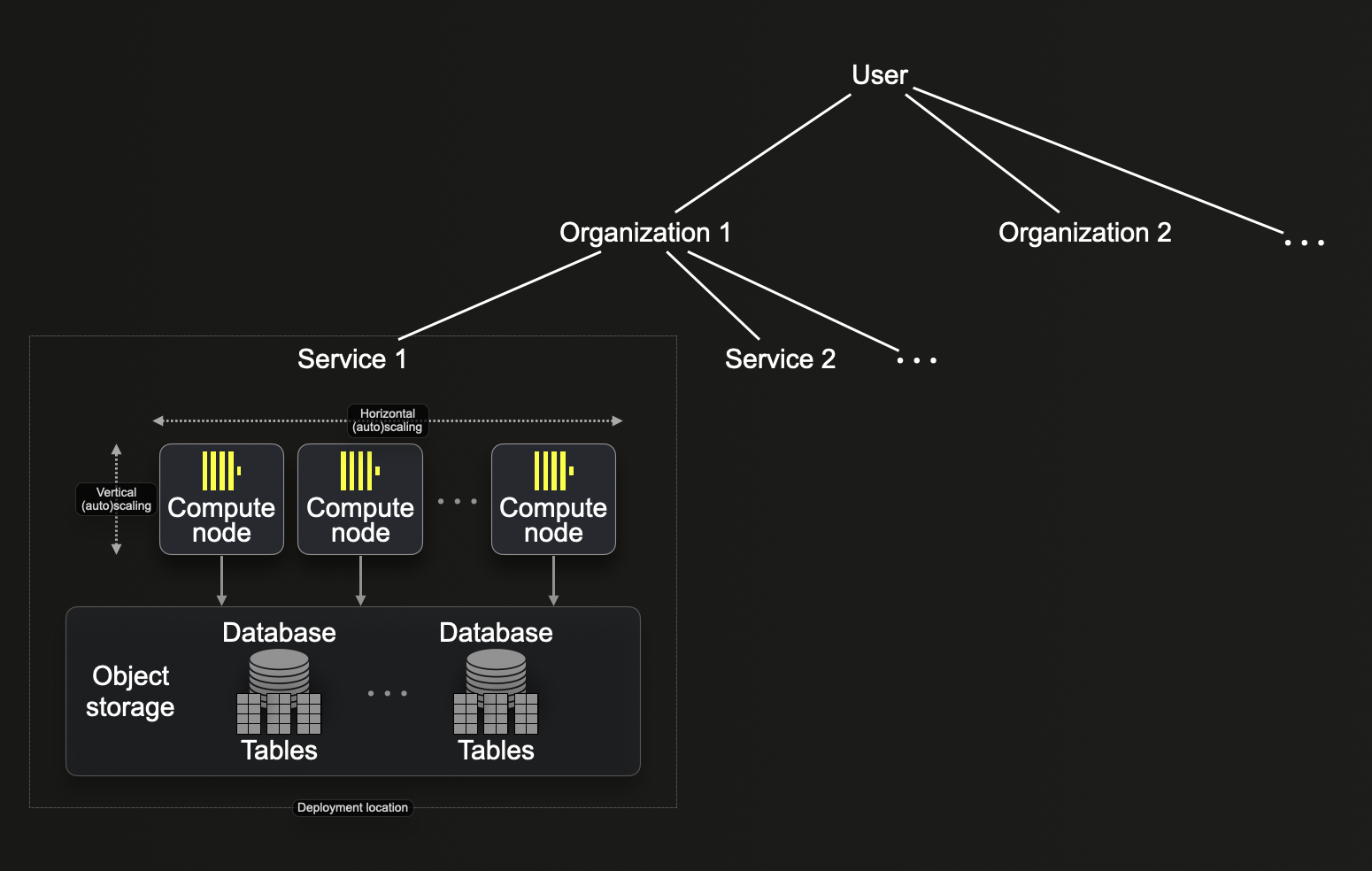
Organizations
Similar to BigQuery, organizations are the root nodes in the ClickHouse cloud resource hierarchy. The first user you set up in your ClickHouse Cloud account is automatically assigned to an organization owned by the user. The user may invite additional users to the organization.
BigQuery Projects vs ClickHouse Cloud Services
Within organizations, you can create services loosely equivalent to BigQuery projects because stored data in ClickHouse Cloud is associated with a service. There are several service types available in ClickHouse Cloud. Each ClickHouse Cloud service is deployed in a specific region and includes:
- A group of compute nodes (currently, 2 nodes for a Development tier service and 3 for a Production tier service). For these nodes, ClickHouse Cloud supports vertical and horizontal scaling, both manually and automatically.
- An object storage folder where the service stores all the data.
- An endpoint (or multiple endpoints created via ClickHouse Cloud UI console) - a service URL that you use to connect to the service (for example,
https://dv2fzne24g.us-east-1.aws.clickhouse.cloud:8443)
BigQuery Datasets vs ClickHouse Cloud Databases
ClickHouse logically groups tables into databases. Like BigQuery datasets, ClickHouse databases are logical containers that organize and control access to table data.
BigQuery Folders
ClickHouse Cloud currently has no concept equivalent to BigQuery folders.
BigQuery Slot reservations and Quotas
Like BigQuery slot reservations, you can configure vertical and horizontal autoscaling in ClickHouse Cloud. For vertical autoscaling, you can set the minimum and maximum size for the memory and CPU cores of the compute nodes for a service. The service will then scale as needed within those bounds. These settings are also available during the initial service creation flow. Each compute node in the service has the same size. You can change the number of compute nodes within a service with horizontal scaling.
Furthermore, similar to BigQuery quotas, ClickHouse Cloud offers concurrency control, memory usage limits, and I/O scheduling, enabling users to isolate queries into workload classes. By setting limits on shared resources (CPU cores, DRAM, disk and network I/O) for specific workload classes, it ensures these queries do not affect other critical business queries. Concurrency control prevents thread oversubscription in scenarios with a high number of concurrent queries.
ClickHouse tracks byte sizes of memory allocations at the server, user, and query level, allowing flexible memory usage limits. Memory overcommit enables queries to use additional free memory beyond the guaranteed memory, while assuring memory limits for other queries. Additionally, memory usage for aggregation, sort, and join clauses can be limited, allowing fallbacks to external algorithms when the memory limit is exceeded.
Lastly, I/O scheduling allows users to restrict local and remote disk accesses for workload classes based on maximum bandwidth, in-flight requests, and policy.
Permissions
ClickHouse Cloud controls user access in two places, via the cloud console and via the database. Console access is managed via the clickhouse.cloud user interface. Database access is managed via database user accounts and roles. Additionally, console users can be granted roles within the database that enable the console user to interact with the database via our SQL console.
Data types
ClickHouse offers more granular precision with respect to numerics. For example, BigQuery offers the numeric types INT64, NUMERIC, BIGNUMERIC and FLOAT64. Contrast these with ClickHouse, which offers multiple precisions for decimals, floats, and ints. With these data types, ClickHouse users can optimize storage and memory overhead, resulting in faster queries and lower resource consumption. Below we map the equivalent ClickHouse type for each BigQuery type:
When presented with multiple options for ClickHouse types, consider the actual range of the data and pick the lowest required. Also, consider utilizing appropriate codecs for further compression.
Query acceleration techniques
Primary and Foreign keys and Primary index
In BigQuery, a table can have primary key and foreign key constraints. Typically, primary and foreign keys are used in relational databases to ensure data integrity. A primary key value is normally unique for each row and is not NULL. Each foreign key value in a row must be present in the primary key column of the primary key table or be NULL. In BigQuery, these constraints are not enforced, but the query optimizer may use this information to optimize queries better.
In ClickHouse, a table can also have a primary key. Like BigQuery, ClickHouse doesn't enforce uniqueness for a table's primary key column values. Unlike BigQuery, a table's data is stored on disk ordered by the primary key column(s). The query optimizer utilizes this sort order to prevent resorting, to minimize memory usage for joins, and to enable short-circuiting for limit clauses. Unlike BigQuery, ClickHouse automatically creates a (sparse) primary index based on the primary key column values. This index is used to speed up all queries that contain filters on the primary key columns. ClickHouse currently doesn't support foreign key constraints.
Secondary indexes (Only available in ClickHouse)
In addition to the primary index created from the values of a table's primary key columns, ClickHouse allows you to create secondary indexes on columns other than those in the primary key. ClickHouse offers several types of secondary indexes, each suited to different types of queries:
- Bloom Filter Index:
- Used to speed up queries with equality conditions (e.g., =, IN).
- Uses probabilistic data structures to determine whether a value exists in a data block.
- Token Bloom Filter Index:
- Similar to a Bloom Filter Index but used for tokenized strings and suitable for full-text search queries.
- Min-Max Index:
- Maintains the minimum and maximum values of a column for each data part.
- Helps to skip reading data parts that do not fall within the specified range.
Search indexes
Similar to search indexes in BigQuery, full-text indexes can be created for ClickHouse tables on columns with string values.
Vector indexes
BigQuery recently introduced vector indexes as a Pre-GA feature. Likewise, ClickHouse has experimental support for indexes to speed up vector search use cases.
Partitioning
Like BigQuery, ClickHouse uses table partitioning to enhance the performance and manageability of large tables by dividing tables into smaller, more manageable pieces called partitions. We describe ClickHouse partitioning in detail here.
Clustering
With clustering, BigQuery automatically sorts table data based on the values of a few specified columns and colocates them in optimally sized blocks. Clustering improves query performance, allowing BigQuery to better estimate the cost of running the query. With clustered columns, queries also eliminate scans of unnecessary data.
In ClickHouse, data is automatically clustered on disk based on a table’s primary key columns and logically organized in blocks that can be quickly located or pruned by queries utilizing the primary index data structure.
Materialized views
Both BigQuery and ClickHouse support materialized views – precomputed results based on a transformation query's result against a base table for increased performance and efficiency.
Querying materialized views
BigQuery materialized views can be queried directly or used by the optimizer to process queries to the base tables. If changes to base tables might invalidate the materialized view, data is read directly from the base tables. If the changes to the base tables don't invalidate the materialized view, then the rest of the data is read from the materialized view, and only the changes are read from the base tables.
In ClickHouse, materialized views can be queried directly only. However, compared to BigQuery (in which materialized views are automatically refreshed within 5 minutes of a change to the base tables, but no more frequently than every 30 minutes), materialized views are always in sync with the base table.
Updating materialized views
BigQuery periodically fully refreshes materialized views by running the view's transformation query against the base table. Between refreshes, BigQuery combines the materialized view's data with new base table data to provide consistent query results while still using the materialized view.
In ClickHouse, materialized views are incrementally updated. This incremental update mechanism provides high scalability and low computing costs: incrementally updated materialized views are engineered especially for scenarios where base tables contain billions or trillions of rows. Instead of querying the ever-growing base table repeatedly to refresh the materialized view, ClickHouse simply calculates a partial result from (only) the values of the newly inserted base table rows. This partial result is incrementally merged with the previously calculated partial result in the background. This results in dramatically lower computing costs compared to refreshing the materialized view repeatedly from the whole base table.
Transactions
In contrast to ClickHouse, BigQuery supports multi-statement transactions inside a single query, or across multiple queries when using sessions. A multi-statement transaction lets you perform mutating operations, such as inserting or deleting rows on one or more tables, and either commit or rollback the changes atomically. Multi-statement transactions are on ClickHouse's roadmap for 2024.
Aggregate functions
Compared to BigQuery, ClickHouse comes with significantly more built-in aggregate functions:
- BigQuery comes with 18 aggregate functions, and 4 approximate aggregate functions.
- ClickHouse has over 150 pre-built aggregation functions, plus powerful aggregation combinators for extending the behavior of pre-built aggregation functions. As an example, you can apply the over 150 pre-built aggregate functions to arrays instead of table rows simply by calling them with a -Array suffix. With a -Map suffix you can apply any aggregate function to maps. And with a -ForEach suffix, you can apply any aggregate function to nested arrays.
Data sources and file formats
Compared to BigQuery, ClickHouse supports significantly more file formats and data sources:
- ClickHouse has native support for loading data in 90+ file formats from virtually any data source
- BigQuery supports 5 file formats and 19 data sources
SQL language features
ClickHouse provides standard SQL with many extensions and improvements that make it more friendly for analytical tasks. E.g. ClickHouse SQL supports lambda functions and higher order functions, so you don’t have to unnest/explode arrays when applying transformations. This is a big advantage over other systems like BigQuery.
Arrays
Compared to BigQuery's 8 array functions, ClickHouse has over 80 built-in array functions for modeling and solving a wide range of problems elegantly and simply.
A typical design pattern in ClickHouse is to use the groupArray aggregate function to (temporarily) transform specific row values of a table into an array. This then can be conveniently processed via array functions, and the result can be converted back into individual table rows via arrayJoin aggregate function.
Because ClickHouse SQL supports higher order lambda functions, many advanced array operations can be achieved by simply calling one of the higher order built-in array functions, instead of temporarily converting arrays back to tables, as it is often required in BigQuery, e.g. for filtering or zipping arrays. In ClickHouse these operations are just a simple function call of the higher order functions arrayFilter, and arrayZip, respectively.
In the following, we provide a mapping of array operations from BigQuery to ClickHouse:
| BigQuery | ClickHouse |
|---|---|
| ARRAY_CONCAT | arrayConcat |
| ARRAY_LENGTH | length |
| ARRAY_REVERSE | arrayReverse |
| ARRAY_TO_STRING | arrayStringConcat |
| GENERATE_ARRAY | range |
Create an array with one element for each row in a subquery
BigQuery
SELECT ARRAY
(SELECT 1 UNION ALL
SELECT 2 UNION ALL
SELECT 3) AS new_array;
/*-----------*
| new_array |
+-----------+
| [1, 2, 3] |
*-----------*/
ClickHouse
groupArray aggregate function
SELECT groupArray(*) AS new_array
FROM
(
SELECT 1
UNION ALL
SELECT 2
UNION ALL
SELECT 3
)
┌─new_array─┐
1. │ [1,2,3] │
└───────────┘
Convert an array into a set of rows
BigQuery
UNNEST operator
SELECT *
FROM UNNEST(['foo', 'bar', 'baz', 'qux', 'corge', 'garply', 'waldo', 'fred'])
AS element
WITH OFFSET AS offset
ORDER BY offset;
/*----------+--------*
| element | offset |
+----------+--------+
| foo | 0 |
| bar | 1 |
| baz | 2 |
| qux | 3 |
| corge | 4 |
| garply | 5 |
| waldo | 6 |
| fred | 7 |
*----------+--------*/
ClickHouse
ARRAY JOIN clause
WITH ['foo', 'bar', 'baz', 'qux', 'corge', 'garply', 'waldo', 'fred'] AS values
SELECT element, num-1 AS offset
FROM (SELECT values AS element) AS subquery
ARRAY JOIN element, arrayEnumerate(element) AS num;
/*----------+--------*
| element | offset |
+----------+--------+
| foo | 0 |
| bar | 1 |
| baz | 2 |
| qux | 3 |
| corge | 4 |
| garply | 5 |
| waldo | 6 |
| fred | 7 |
*----------+--------*/
Return an array of dates
BigQuery
GENERATE_DATE_ARRAY function
SELECT GENERATE_DATE_ARRAY('2016-10-05', '2016-10-08') AS example;
/*--------------------------------------------------*
| example |
+--------------------------------------------------+
| [2016-10-05, 2016-10-06, 2016-10-07, 2016-10-08] |
*--------------------------------------------------*/
ClickHouse
SELECT arrayMap(x -> (toDate('2016-10-05') + x), range(toUInt32((toDate('2016-10-08') - toDate('2016-10-05')) + 1))) AS example
┌─example───────────────────────────────────────────────┐
1. │ ['2016-10-05','2016-10-06','2016-10-07','2016-10-08'] │
└───────────────────────────────────────────────────────┘
Return an array of timestamps
BigQuery
GENERATE_TIMESTAMP_ARRAY function
SELECT GENERATE_TIMESTAMP_ARRAY('2016-10-05 00:00:00', '2016-10-07 00:00:00',
INTERVAL 1 DAY) AS timestamp_array;
/*--------------------------------------------------------------------------*
| timestamp_array |
+--------------------------------------------------------------------------+
| [2016-10-05 00:00:00+00, 2016-10-06 00:00:00+00, 2016-10-07 00:00:00+00] |
*--------------------------------------------------------------------------*/
ClickHouse
SELECT arrayMap(x -> (toDateTime('2016-10-05 00:00:00') + toIntervalDay(x)), range(dateDiff('day', toDateTime('2016-10-05 00:00:00'), toDateTime('2016-10-07 00:00:00')) + 1)) AS timestamp_array
Query id: b324c11f-655b-479f-9337-f4d34fd02190
┌─timestamp_array─────────────────────────────────────────────────────┐
1. │ ['2016-10-05 00:00:00','2016-10-06 00:00:00','2016-10-07 00:00:00'] │
└─────────────────────────────────────────────────────────────────────┘
Filtering arrays
BigQuery
Requires temporarily converting arrays back to tables via UNNEST operator
WITH Sequences AS
(SELECT [0, 1, 1, 2, 3, 5] AS some_numbers
UNION ALL SELECT [2, 4, 8, 16, 32] AS some_numbers
UNION ALL SELECT [5, 10] AS some_numbers)
SELECT
ARRAY(SELECT x * 2
FROM UNNEST(some_numbers) AS x
WHERE x < 5) AS doubled_less_than_five
FROM Sequences;
/*------------------------*
| doubled_less_than_five |
+------------------------+
| [0, 2, 2, 4, 6] |
| [4, 8] |
| [] |
*------------------------*/
ClickHouse
arrayFilter function
WITH Sequences AS
(
SELECT [0, 1, 1, 2, 3, 5] AS some_numbers
UNION ALL
SELECT [2, 4, 8, 16, 32] AS some_numbers
UNION ALL
SELECT [5, 10] AS some_numbers
)
SELECT arrayMap(x -> (x * 2), arrayFilter(x -> (x < 5), some_numbers)) AS doubled_less_than_five
FROM Sequences;
┌─doubled_less_than_five─┐
1. │ [0,2,2,4,6] │
└────────────────────────┘
┌─doubled_less_than_five─┐
2. │ [] │
└────────────────────────┘
┌─doubled_less_than_five─┐
3. │ [4,8] │
└────────────────────────┘
Zipping arrays
BigQuery
Requires temporarily converting arrays back to tables via UNNEST operator
WITH
Combinations AS (
SELECT
['a', 'b'] AS letters,
[1, 2, 3] AS numbers
)
SELECT
ARRAY(
SELECT AS STRUCT
letters[SAFE_OFFSET(index)] AS letter,
numbers[SAFE_OFFSET(index)] AS number
FROM Combinations
CROSS JOIN
UNNEST(
GENERATE_ARRAY(
0,
LEAST(ARRAY_LENGTH(letters), ARRAY_LENGTH(numbers)) - 1)) AS index
ORDER BY index
);
/*------------------------------*
| pairs |
+------------------------------+
| [{ letter: "a", number: 1 }, |
| { letter: "b", number: 2 }] |
*------------------------------*/
ClickHouse
arrayZip function
WITH Combinations AS
(
SELECT
['a', 'b'] AS letters,
[1, 2, 3] AS numbers
)
SELECT arrayZip(letters, arrayResize(numbers, length(letters))) AS pairs
FROM Combinations;
┌─pairs─────────────┐
1. │ [('a',1),('b',2)] │
└───────────────────┘
Aggregating arrays
BigQuery
Requires converting arrays back to tables via UNNEST operator
WITH Sequences AS
(SELECT [0, 1, 1, 2, 3, 5] AS some_numbers
UNION ALL SELECT [2, 4, 8, 16, 32] AS some_numbers
UNION ALL SELECT [5, 10] AS some_numbers)
SELECT some_numbers,
(SELECT SUM(x)
FROM UNNEST(s.some_numbers) AS x) AS sums
FROM Sequences AS s;
/*--------------------+------*
| some_numbers | sums |
+--------------------+------+
| [0, 1, 1, 2, 3, 5] | 12 |
| [2, 4, 8, 16, 32] | 62 |
| [5, 10] | 15 |
*--------------------+------*/
ClickHouse
arraySum, arrayAvg, … function, or any of the over 90 existing aggregate function names as argument for the arrayReduce funtion
WITH Sequences AS
(
SELECT [0, 1, 1, 2, 3, 5] AS some_numbers
UNION ALL
SELECT [2, 4, 8, 16, 32] AS some_numbers
UNION ALL
SELECT [5, 10] AS some_numbers
)
SELECT
some_numbers,
arraySum(some_numbers) AS sums
FROM Sequences;
┌─some_numbers──┬─sums─┐
1. │ [0,1,1,2,3,5] │ 12 │
└───────────────┴──────┘
┌─some_numbers──┬─sums─┐
2. │ [2,4,8,16,32] │ 62 │
└───────────────┴──────┘
┌─some_numbers─┬─sums─┐
3. │ [5,10] │ 15 │
└──────────────┴──────┘