A columnar database stores the data of each column independently. This allows reading data from disk only for those columns that are used in any given query. The cost is that operations that affect whole rows become proportionally more expensive. The synonym for a columnar database is a column-oriented database management system. ClickHouse is a typical example of such a system.
Key columnar database advantages are:
- Queries that use only a few columns out of many.
- Aggregating queries against large volumes of data.
- Column-wise data compression.
Here is the illustration of the difference between traditional row-oriented systems and columnar databases when building reports:
Traditional row-oriented
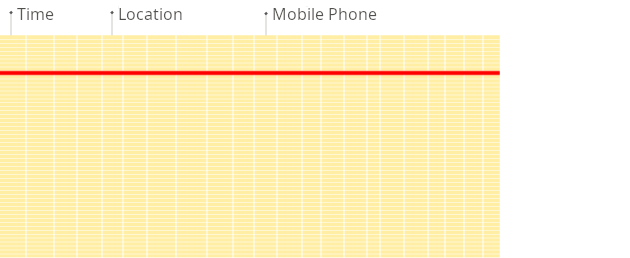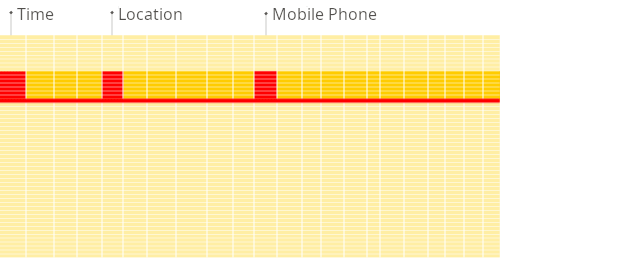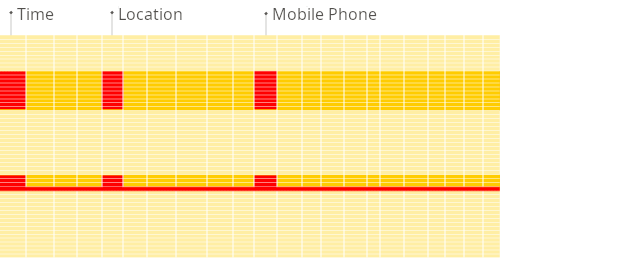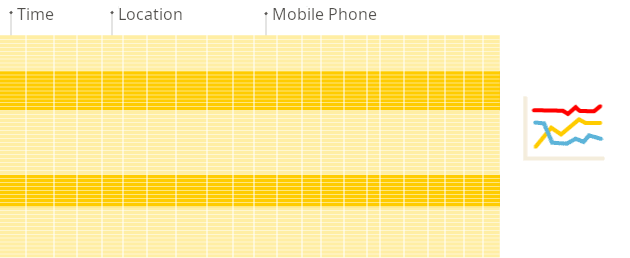
Columnar
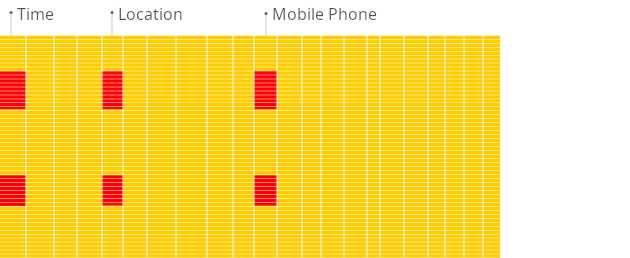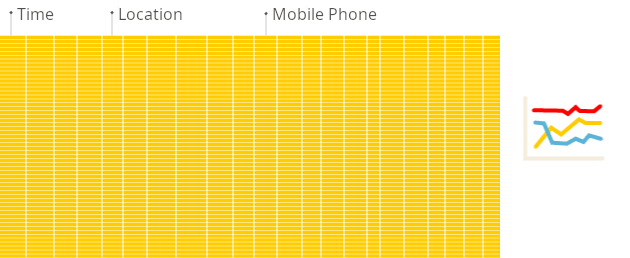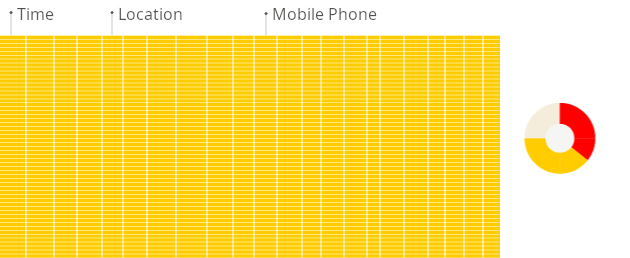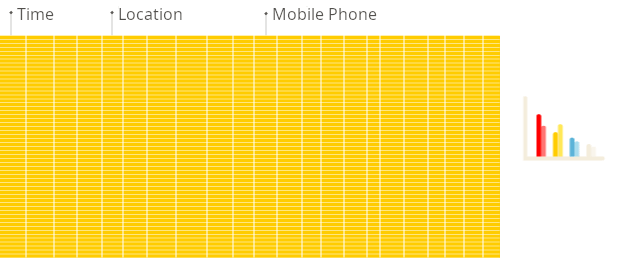
A columnar database is the preferred choice for analytical applications because it allows having many columns in a table just in case, but to not pay the cost for unused columns on read query execution time (a traditional OLTP database reads all of the data during queries as the data is stored in rows and not columns). Column-oriented databases are designed for big data processing and data warehousing, they often natively scale using distributed clusters of low-cost hardware to increase throughput. ClickHouse does it with combination of distributed and replicated tables.